Caching Unlocked
Learn how to avoid common pitfalls, optimize cache performance, and build systems that scale seamlessly.
Executive Summary
You’re building a high-performance application where data retrieval speed is crucial. Each database call adds latency, but caching can reduce this overhead. However, implementing the right caching strategy—whether it’s read-through, write-through, or a dynamic approach—can be complex. In this post, we’ll explore how to implement caching strategies, from ensuring your cache always provides fresh data to optimizing performance through real-time cache management. We’ll explore code examples using Spring Boot and Redis, demonstrating how to balance efficiency, reliability, and scalability in an e-commerce application. The full example can be found in the GitHub repository.
Is It Cachable ?
Before diving into the various caching strategies, let’s first address a fundamental question: What makes something cachable?
Not all data is suited for caching, and determining what should be cached is crucial for optimizing performance. Here is the inspiration from Duane Wessels’ Web Caching explains:
A response is said to be
cachableif it can be used to answer a future request.
This simple yet powerful definition highlights the essence of cacheability – data that can be stored and reused efficiently is worth caching, while other types might not benefit from it.
Cache Placement
Caching can be placed in three key places, each serving a different purpose in reducing latency.
Browser Cache- Stores data directly in the client-side browser, to reduce load times for frequently accessed resources.Proxy Cache- A shared cache between clients and servers, often used inCDN’s to store and serve data closer to the userApplication Cache- This is typically implemetned on the server-side or in a distributed cache system like Redis, this cache provides faster data retrieval and reducing database load.
In this blog we’ll primarly focus on Application Caching, which is central to server-side performance optimization.
Caching Strategies
We start with data either a pre-existing or generated as needed. At some point, we need to retrieve that data. When analyzing how we access it, we can determine our system is read-intensive, or write-intensive, or a combination of both, depending on the use case. By identifying this patterns early on, we can minimize latency and improve the overall performance of read operations. But what about write-heavy scenarios ? In real-world case such as movie reservation system where many users might compete for the same seat, write-through caching ensures that customers are served fairly.
Read Heavy Strategies
Read Through
As the names suggest, we first check the cache for the requested data- if it’s there(a cache hit), we serve it directly. If not, the system will fetch the data from the source and cache it for future requests. On a subsequent request, the cache will serve the data, bypassing the expensive route to the data source as long as the data hasn’t expired. This minimizes latency by reducing the need for costly operations.
Refresh Ahead
Much like Neo in The Matrix, who anticipates moves before they happen. The Refresh-Ahead strategy predicts the future data requests. It proactively loads data into the cache before it’s needed, ensuring that when the user requests it, the data is already ready and waiting.
Write Heavy Strategies
Write Through
In a write through strategy, data is written to the cache and the data source simultaneously. This ensures consitency between the cache and the underlying data source, but it comes with a tradeoff– introducing latency during the write operation.
This approach is particularly useful in write heavy scenarios, such as ordering a product in an e-commerce platform. By ensuring updates to both the cache and the data source, we can minimize issues like overselling or stock inconsistency, delivering a seamless experience for users.
Write Behind
In this strategy, the data is written to the cache immediately but the write to the data source is delayed and performed asynchronously. This approach allows for flexibility, as the timing and frequency of writes to the data can be tailored to business use cases.
For instance, consider an e-commerce scenario where customers add items to their cart. It might not make sense to write this data to the data source immediately. Instead, the system coulld load it into the cache and only write it to the data source when the customer completes the purchase.
However, this strategy comes with tradeoffs. There is a risk of not updating the data source if a failure occurs, leading to potential incosistencies. The cache could hold outdated data if the data source isn’t updted in time. Proper safegurds, like retry mechanisms or durability measures are necessary to mitigate these risks.
Cache Invalidation
If the cache holds outdated or stale data, it could lead to inconsistencies, incorrect results or poor customer experience. Let’s explore several strategies for invalidating cached data to ensure it remains fresh, accurate and aligned with the source of truth.
Invalidating on Modification
When implementing this strategy, there are two key aspects to focus on: update and delete operations.
Update: Whenever there is an update to the data, we need to invalidate the corresponding cache entry to ensure that subsequent requests fetch the updated data from the data source.Delete: Similarly, when an entry is deleted, the cache should be invalidated to ensure that the deleted data doesn’t persist in the cache. When the data is requested again, it will be fetched from the data source and the cache will be repopulated with the latest or empty data.
Invalidating on Read
When we receive a read request, we can check the freshness of the data to determine whether we need to retrieve it from the data source.
One way to achieve invalidation on read is in an e-commerce use case where product details, such as prices, are frequently updated. By using the last updated timestamp, we can determine if the cached data is stale. The full example can be found in the GitHub repository.
The implementation is a work in progress, but you can already explore key concepts and examples discussed in this article.
1
2
3
4
5
6
7
8
9
10
11
@Cacheable(value = "productCache", key = "#id", unless = "#result == null || #result.isStale()")
public ProductDTO getProductById(Long id) {
Optional<Product> product = productRepository.findById(id);
return product.map(mapper::convert)
.orElseThrow(() -> new ProductNotFoundException("Product with ID '" + id + "' not found"));
}
// In the DTO, we can have an isStale function to check the freshness of the data
public boolean isStale() {
return lastUpdated == null || Instant.now().minusSeconds(60).isAfter(lastUpdated);
}
Time to Live (TTL)
Another strategy to keep cache data fresh and relevant is to set an appropriate time to invalidate the cache. The expiration time should be determined by business use cases and should not be static. It needs to be updated based on data access patterns and the frequency of requests and updates. This ensures that the cache remains efficient and accurate.
In a Spring Boot application, you can configure the TTL for your cache directly in the application.yml file. This approach allows you to manage cache settings without changing the code, making it easier to adjust configurations based on different environments or requirements.
1
2
3
4
spring:
cache:
redis:
time-to-live: 30m
Observability Driven
To truly optimize our caching strategy and enhance customer satisfaction, we must first understand how our data is being accessed. This is where observability comes into play– by tracking key metrics, we can gain the insights necessary to refine our approach.
Key Metrics
Cache Hits and Misses: Track how often data is retrieved from the cache vs the data source. This will help identify areas where caching is most effective and where improvements needed.Access Frequency: Determine which data points are accessed most frequently and which ones are infrequently used. This insight helps prioritize what data should be cached.Response Times: Measure how long it takes to fetch data from the source.Time of Access: Analyze when data is accessed, especially during peak hours. This allows us to predict demand and adjust cache preloading strategies accordingly.
Monitoring with Redis and Grafana
Observability is only as powerful as the tools used to act on it. To track Redis performance and gain real-time insights, we rely on preconfigured Grafana dashboard. It provides a clear view of key Redis metrics.
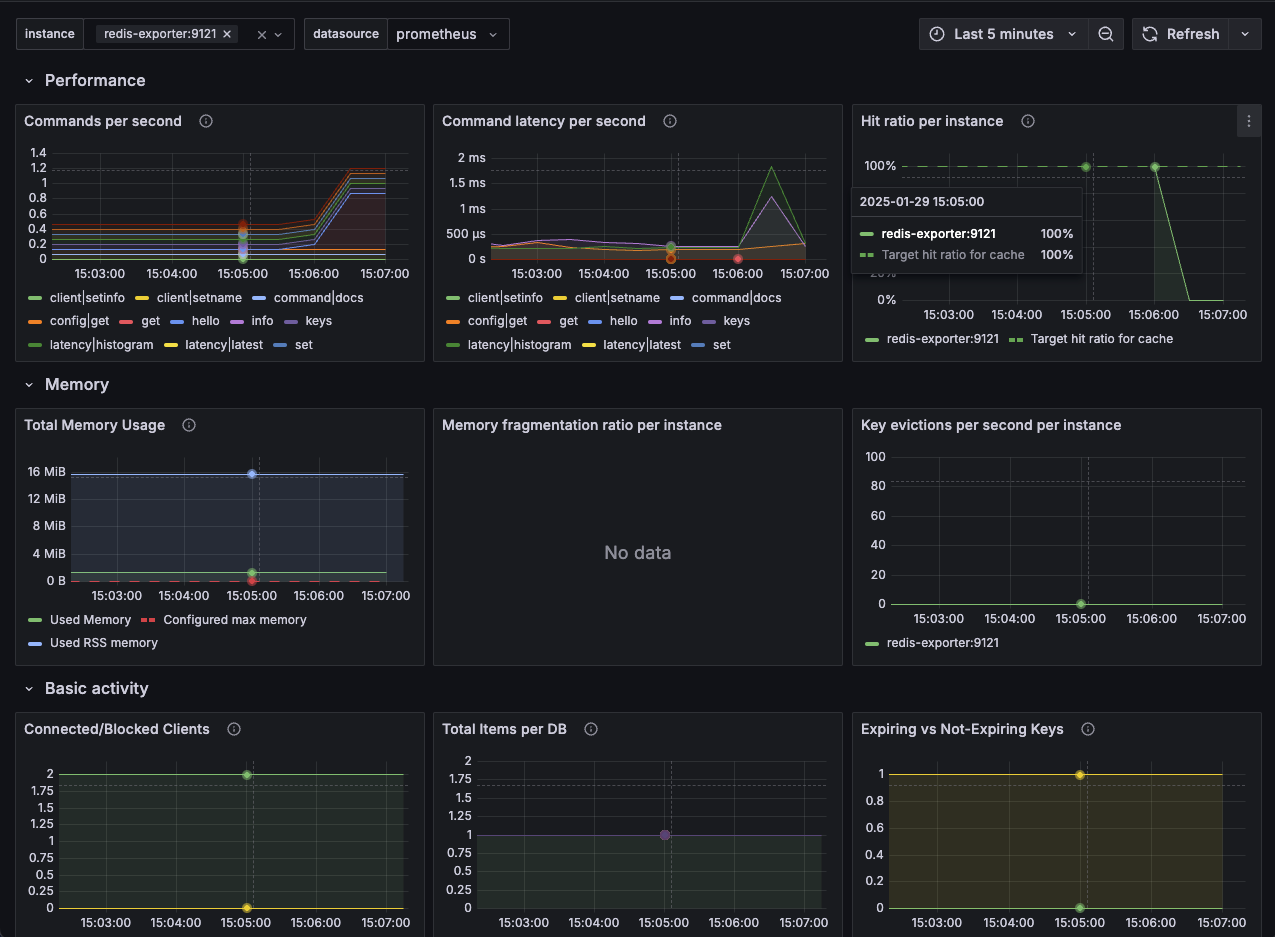
Once you access the dashboard, pay close attention to the cache hit ratio.
1
hit_ratio = keyspace_hits / (keyspace_hits + keyspace_misses)
This ratio helps you gauge how effectively Redis is serving cached data. A drop here can indicate performance issues.
To verify cache contents directly, you can check Redis using the command line:
1
2
3
4
5
6
7
8
9
10
11
12
docker exec -it redis sh
# redis-cli KEYS "*"
1) "product-service-productCache::1"
# redis-cli GET "product-service-productCache::1" | jq .
{
"name": "Apple iPhone 15 Pro",
"description": "The latest iPhone with A17 Bionic chip, titanium design, and advanced camera features.",
"price": 999.99,
"category": {
"name": "Electronics"
}
}
Next, monitor Command Latency per second. This metric shows the time taken between the client’s request and Redis’s response. Increased latency often points to resource contention.
When you notice an unusual drop in these or other metrics, investigate further by checking total memory usage and key evictions. These can guide your strategy for optimizing Redis performance, ensuring that you address potential issues like memory shortages or inefficient eviction policies before they impact your system.
Conclusion
In this article, we explored various caching strategies—including read-through, refresh-ahead, write-through, and write-behind—to address performance and consistency challenges. We demonstrated how each method optimizes data retrieval and maintains data freshness. By applying these techniques, you can build scalable systems that effectively reduce latency and improve user experience.